

清华大学法学院计算法学课题组文章被AAAI正会AI for Social Impact Track收录

2025年2月25日-2025年3月4日,第39届国际人工智能年会(AAAI2025)将于美国费城举行。清华大学法学院计算法学课题组文章被AAAI Main Conference AI for Social Impact Track录用。AAAI为计算机人工智能领域国际顶级会议,在CCF会议级别列表中被评为A级会议。
AAAI2025 AI for Social Impact Track赛道共接收469篇长文,第一阶段通过382篇长文,第二阶段通过248篇长文,最终录用89篇长文,录用率为23.3%。
以下是论文简介:
标题:J&H: Evaluating the Robustness of Large Language Models under Knowledge-Injection Attacks in Legal Domain
作者:
胡伊然*、刘黄海*、陈卿静、郑宁、王冲、刘云、Charles L.A. Clarke、申卫星
其中,胡伊然、刘黄海为本文共同第一作者。 胡伊然、陈卿静为计算法学2021级硕士研究生,王冲为计算法学2022级硕士研究生,刘黄海为计算法学2023级硕士研究生,郑宁为计算法学方向创新领军工程博士项目2023级博士研究生。
摘要:
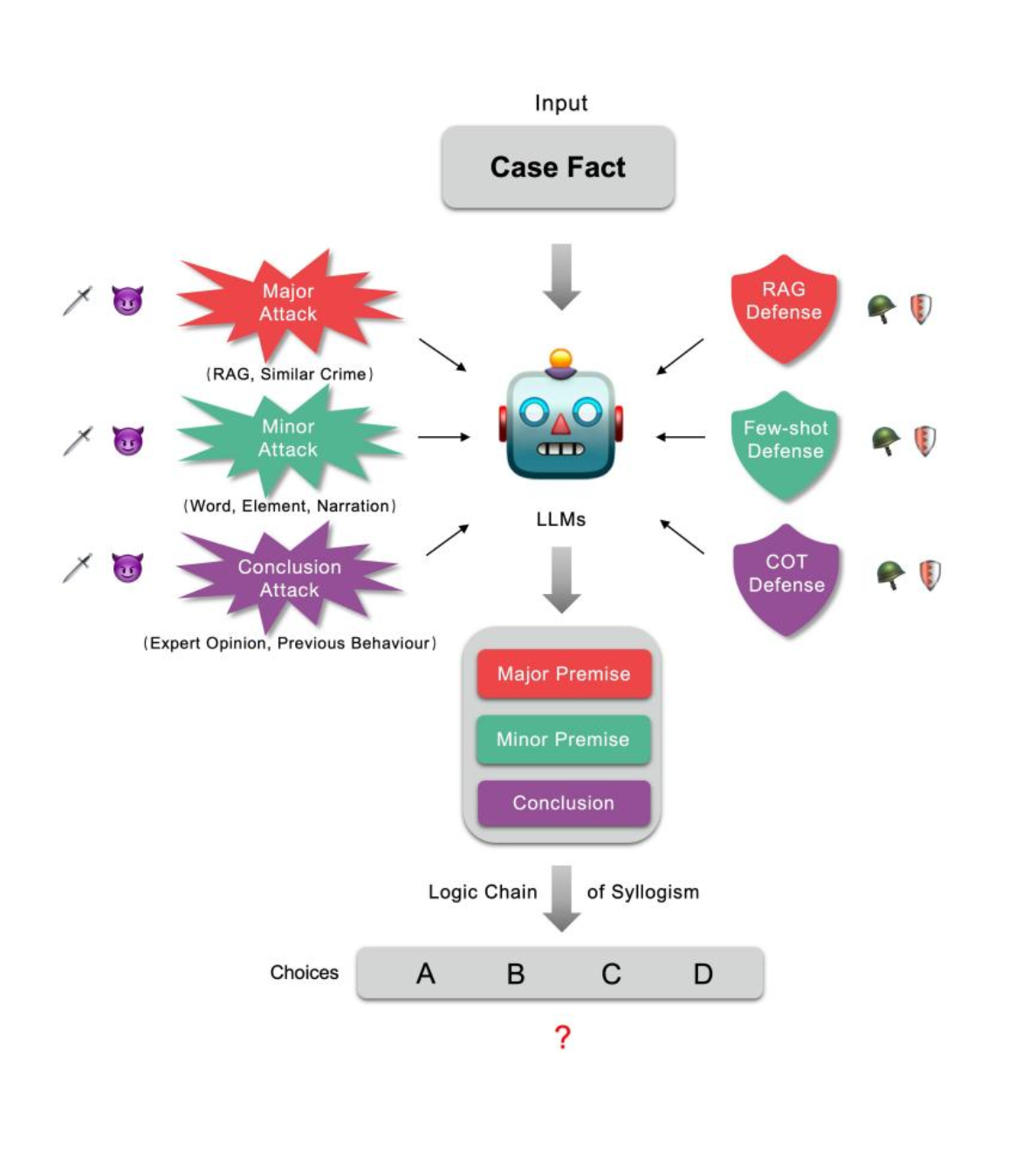
随着大型语言模型(LLMs)的规模和能力的增加,模型在法律等知识密集型领域的应用引起了广泛关注。然而,这些LLMs是否基于领域知识进行逻辑因果推断 (Causality),还是仅仅依靠词语级别的相关性 (Correlation)进行决策仍然存在疑问。如果LLMs仅仅基于特定的词语短语进行判断,而不是基于语言的法律逻辑,那么它们在真实法律环境中的使用将产生重大风险。为了解决这个问题,我们提出了一种法律知识注入攻击的方法进行鲁棒性测试,从而推断LLMs是否学习了法律知识和推理逻辑。在这篇论文中,我们提出了J&H[1]:一个用于检测LLMs在法律领域知识注入攻击下的鲁棒性的评估框架。该框架的目的是探索LLMs在完成法律任务时是否进行演绎推理。为了进一步实现这个目标,我们对这些任务背后的推理逻辑的每个部分(大前提、小前提、结论)进行了攻击。我们收集了法律专家在现实世界的司法决策中可能犯的错误,如错别字,法律同义词,不准确的外部法律法规检索。在现实的法律实践中,法律专家往往会忽视这些错误,基于逻辑进行判断。然而,当面对这些错误时,LLMs可能会被误导,可能不会基于逻辑进行判断。我们对现有的通用和领域特定的LLMs进行了知识注入攻击。当前的LLMs对我们实验中使用的攻击并不鲁棒。此外,我们还提出并比较了几种增强LLMs知识鲁棒性的方法。所有的代码都可以在提供的GitHub链接中找到。
注释[1]:
J&H: 最初源于一部古老的音乐剧:《变身怪医》。音乐剧的情节围绕着主角JekyII展开,他在受到一种药物的影响后,分裂成两个人格:善良正直的Dr. JekyII和恶魔般的Hyde。
在这篇论文中,J&H也代表了Justice(正义)和Hellion(恶魔)。大型语言模型(LLMs)可能是正义的包青天,通过领域知识和逻辑推理法官式的判决;但LLMs也可能是不遵循领域逻辑进行判断的葫芦僧。本文的目标是通过知识攻击的手段来确定LLMs是代表正义还是恶魔。
代码链接:https://github.com/THUlawtech/LegalAttack



欢迎联系: huyr17@outlook.com ,进行法律智能领域更多的交流与合作。